To demonstrate the simplicity of utilizing technologies such as AWS Lambda, Python, and DynamoDB, I developed a simple solution capable of providing periodic information updates (every hour, day, or week) regarding specific data changes on designated URLs.
I will show a straightforward method for creating a web scraping service, enabling you to extract data from various websites and generate e-mail notifications when the system detects noteworthy changes on the targeted sites. This could include job advertisements, articles from specific individuals, or awaiting data publication.
This approach empowers you to construct a scalable, cost-effective solution for extracting and storing URL data.
What is web scraping?
A web scraping is a process of extracting relevant data from websites. A scraping tool, or website scraper, is used as part of the web scraping process to make HTTP requests on a target website and extract web data from a designated page. It parses content that is publicly accessible and visible to the users and rendered by the server as HTML.
Some of the main use cases of web scraping include price monitoring, price intelligence, news monitoring, lead generation, and market research among many others. In general, it is used by people and businesses who want to make use of publicly available web data to generate valuable insights and make smarter decisions.
Prerequisites
Before diving into the implementation, ensure you have the following in place:
- AWS Account: Sign up for an AWS account if you don’t already have one. After creating the root account, avoid using it for regular AWS access. Instead, create a new user account and use IAM to grant it the necessary permissions to work with AWS.
- AWS SAM CLI: Install the AWS Serverless Application Model (SAM) Command Line Interface for local development.
- Visual Studio Code: Although not mandatory, installing Visual Studio Code is recommended to simplify development, especially for managing complex solutions.
For this project, I chose to use AWS Lambda with Python and two third-party Python libraries: BeautifulSoup for web scraping and Boto3 for interacting with DynamoDB. This setup will allow Lambda to monitor specific websites and detect changes in given words or phrases. For instance, if you’re tracking a job listing website for a specific position (e.g., “Software Developer”), this setup will notify you when that listing appears or changes on the targeted site.
If you don’t yet have an AWS account, create one to follow along and test this project.
Steps you need to do to test this web scraping solution
There are a few steps to complete before testing this solution. First, create a DynamoDB table and set up SNS. Next, configure the AWS SAM CLI environment locally, clone the project from GitHub, open it in Visual Studio Code, and deploy it on AWS. To start the project, ensure the correct policies are set for the project role in AWS IAM. I’ll explain each step in detail below.
Create the DynamoDB table
Under AWS DynamoDB, go to Tables (left side menu) and create the table, with items shown below:
- ID (Number) __is a partition key
- FIT (Binary)
- TEXT (String)
- URL (String)
There is also a way to create a DynamoDB Table using AWS SAM and template.yaml, but I will keep this blog simple.
The FIT item indicates whether we are monitoring for the presence of specific text in the TEXT item (status set to TRUE) or looking for text that differs from the TEXT item (status set to FALSE).
For example, if a job site currently displays “no open vacancies,” setting FIT to FALSE will notify us when the website content changes to anything other than “no open vacancies.”
In this setup:
- TEXT item specifies the target text we are monitoring.
- URL is the website from which we scrape the data.
Deployment using AWS SAM CLI
There are many articles on using AWS SAM CLI to deploy the lambda function on AWS, so I will not focus on deployment. Here is an article about the deployment lambda function using AWS SAM CLI: https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/serverless-getting-started-hello-world.html
Create and deploy an AWS Lambda Function
To start using the AWS Lambda function, you need to clone the project locally. Python source code is given on GitHub address: https://github.com/jhadzigrahic/webcrawler-app
To clone the code from the sns-email-notification branch, use the following command:
git clone -b sns-email-notification https://github.com/jhadzigrahic/webcrawler-app
import requests
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
import pandas as pd
from datetime import date # Built-in Python library
import json # Built-in Python library
import boto3
import re
import logging # Built-in Python library
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def scrape_site(url, text):
try:
# Request the page's html script
hdr = {'User-Agent': 'Mozilla/5.0'}
req = Request(url,headers=hdr)
page = urlopen(req)
# Then parse it
soup = BeautifulSoup(page, "html.parser")
# Search for the text
html_lists = soup.find_all(string=re.compile(text))
return len(html_lists)>0
except Exception as e:
logger.error(f"Error scraping {url}: {e}")
return False
def lambda_handler(event, context):
try:
logger.info('Start data retriving...')
# Prepare the DynamoDB client
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('TABLE_NAME')
# Initialize variables for pagination
last_evaluated_key = None
while True:
# Perform a paginated scan
if last_evaluated_key:
response = table.scan(ExclusiveStartKey=last_evaluated_key)
else:
response = table.scan()
for item in response['Items']:
# Extract and process attributes
attrFIT_value = item['FIT']
attrTEXT_value = item['TEXT']
attrURL_value = item['URL']
# Scrape the website
scrape_value=scrape_site(url=attrURL_value, text=attrTEXT_value)
# The FIT item is used to stop the execution of the function (if its value is FALSE),
# because we are looking for data different from the TEXT item.
if not attrFIT_value:
scrape_value = not scrape_value
if scrape_value:
# Prepare the SNS client and send the message
sns = boto3.client('sns')
# creating and sending an e-mail message
# The address of the TopicArn is generic. Please create your own TopicArn through AWS.
response = sns.publish(
TopicArn='arn:aws:sns:eu-west-1:0123456789:MyTestTopic',
Message = 'Sistem found a match on the URL: ' + attrURL_value,
Subject = 'You have an AWS webcrawler matching'
)
# Update the last evaluated key
last_evaluated_key = response.get('LastEvaluatedKey')
# If there's no more data to retrieve, exit the loop
if not last_evaluated_key:
break
logger.info('Data retrieval complete!')
except Exception as e:
logger.error(f"Error in lambda handler: {e}")
Personalize this code for your AWS account by:
- Updating the DynamoDB table name to match the table created under your AWS account.
- Replacing TopicArn value with TopicArn you created under your AWS account.
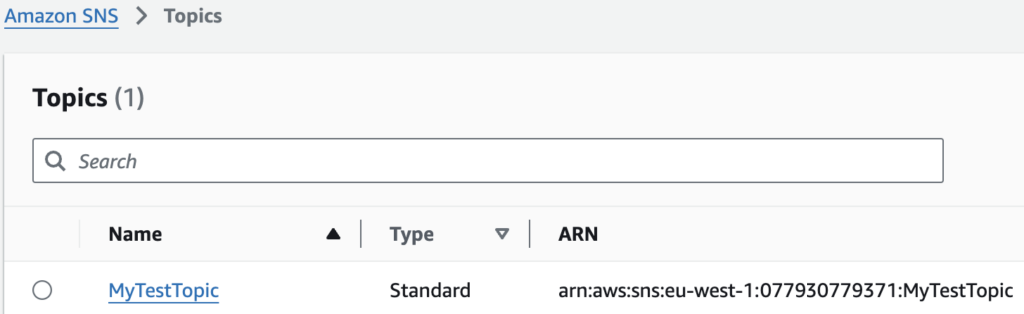
Set up TopicARN
To send an email message, I initially used the AWS SNS (Simple Notification Service) service, which allows sending plain text emails (and SMS messages). However, in the latest release of this Lambda function, I replaced AWS SNS with AWS SES, which provides the ability to send HTML-formatted emails and many additional options.
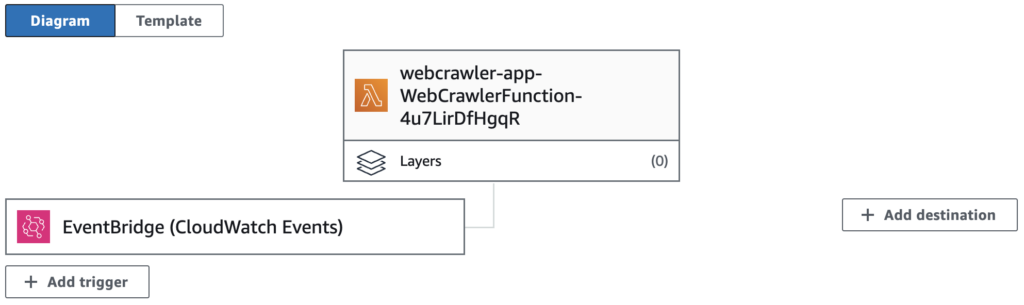
Set up Event Trigger
My idea is to trigger the AWS Lambda function once a day, but you can do it as often as you want. The event trigger I used is AWS EventBridge.
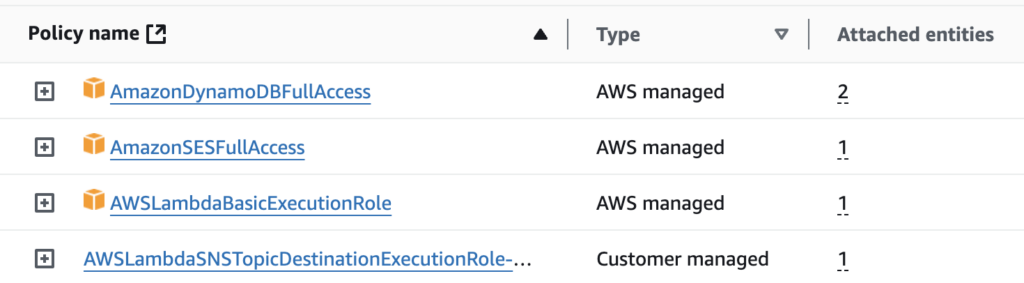
How to grant the Lambda function the necessary permissions to access a DynamoDB table?
Go to AWS IAM, click on Roles in the left menu, then find the role associated with your Lambda function (starting with webcrawler-app-). Once you click on it, you’ll be able to see the attached policies.”
Test and Monitor
Test your Lambda function to ensure it successfully scrapes the websites in DynamoDB and that you can receive an email notification. Monitor the CloudWatch Logs for any errors or issues.
Conclusion
In conclusion, building an AWS Lambda function with Python, Boto3, and BeautifulSoup provides an efficient and scalable solution for web scraping. Leveraging AWS Lambda’s serverless architecture eliminates the need for manual server management, reducing operational overhead. Boto3 enables seamless integration with AWS services like S3, SNS, and DynamoDB, allowing for straightforward data storage and alerting systems. Using BeautifulSoup for web scraping ensures flexible and robust extraction of data from HTML and XML files. Together, these tools offer a powerful combination for automating data retrieval and processing tasks, with AWS Lambda delivering scalability and cost-effectiveness for managing diverse workloads.
In my experience, running AWS Lambda daily for web scraping a few websites incurs no significant cost.